皆さまこんにちは。今回も“問題解決実践編”です。今回は “社内で眠っているデータの徹底活用”を取り上げます。私はこれまでのキャリアの中で、“データは色々あるんだけど、全然活用できていない”という声をよく聞いてきました。また実際に自分が属してきた会社の中でも、誰が何に活用しているのかよくわからない顧客調査の結果等をたくさん見てきました。今回は、そのような“眠っているデータ”の活用方法をご紹介します。
よくある調査結果の例
今回の題材として、いわゆる基本的な集計結果をまとめていて、かつその集計のローデータもダウンロードできるようなオープンデータを探しました。この手のオープンデータは大手の調査会社が数多く公開しています。その中で、今回見つけたのがこちらのオープンデータ(「プライベートブランド」に関する調査結果)です。この中から、幾つか集計結果を見てみます。
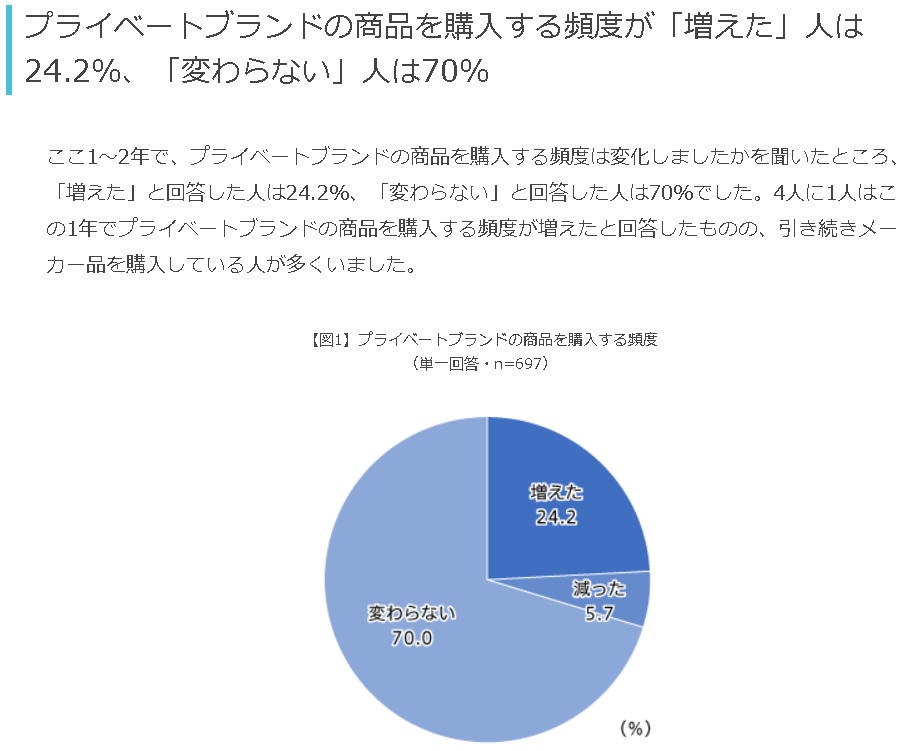
まずプライベートブランド商品を購入する頻度の増減を聞いています。これを見ると“大半の人が変わってないのね”と読み取れると思います。

次いでプライベートブランド商品を購入する際に重視する要素を聞いています。これを見ると“やっぱり価格が大事だね”、“でも品質も過半数が挙げているよ。品質も大事だね”と読み取れると思います。
いかがでしょうか?恐らく多くの方の感覚とずれていないので否定されることもないと思いますが、“なるほど!”ともならずに、“ふ~ん、そうなのね”位の捉え方をされてそのまま“眠りに入り”そうな感じです。
(注)決して、こちらの調査会社様をディスっている訳ではなく、オープンデータは無難な内容に留めて、突っ込んだ分析は別途相談とされている調査会社様が多いことを付け加えさせていただきます。
データの徹底活用
ローデータの確認
それではデータの徹底活用のために、ローデータの中身を確認してみます。
性別
年齢
年代
未既婚
居住地
知っているプライベートブランド(複数選択)
プライベートブランド別のイメージ(複数選択)
ここ1~2年での、プライベートブランドの購入頻度の変化(増えた・減った・変わらない)
上記の理由(自由回答)
この1年以内に、プライベートブランドに切り替えた食品(複数選択)
この1年以内に、プライベートブランドに切り替えた調味料(複数選択)
この1年以内に、プライベートブランドに切り替えた飲料(複数選択)
この1年以内に、プライベートブランドに切り替えた医薬品(複数選択)、等々
こんな時は、“まず重回帰分析”!
上記のような顧客調査結果等の、カラム(列)がたくさんあるデータを見つけた場合には、まず重回帰分析を試してみましょう! ※決定木分析でもいいですね。決定木分析については、また改めて書いてみたいと思います(書きました!⇒こちら)。
重回帰分析でまず考えないといけないのは、何を目的変数とし、何を説明変数とするか、です。目的変数は、“売上”や“顧客満足度”等といった何らかの活動に対する結果、ですね。説明変数は、その“結果”を予測するための変数です。
上記ローデータのカラムを眺めてみて、目的変数となりそうなのが、まず“ここ1~2年での、プライベートブランドの購入頻度の変化(増えた・減った・変わらない)”ですね。また“この1年以内に、プライベートブランドに切り替えた食品/調味料/飲料/医薬品”も使えそうです。
ここで、それらのカラムのデータを実際に眺めてみたいと思います。

“ここ1~2年での、プライベートブランドの購入頻度の変化(増えた・減った・変わらない)”は(1/2/3)、“この1年以内に、プライベートブランドに切り替えた食品/調味料/飲料/医薬品”は(0/1)といった選択式の回答結果になっています。これらのような、数字ではあるものの、選択肢に振られた番号というだけで、大小を表す訳でもなく、計算しても意味がないようなデータタイプのことを“離散変数”と言います。統計学特有の取っつきにくいネーミングですが笑、これはそのまま覚えましょう。
離散変数とは反対に、数字データで大小があり、計算することに意味があるデータタイプのことを“連続変数”と言います。これらのデータタイプの違いによって、使える統計手法が変わってくるので注意してください。
で、上記のように、目的変数が“離散変数”となる場合、重回帰分析の中でも“ロジスティック回帰分析”という手法が使われます(ロジスティック回帰分析については、また改めて当ブログで書いてみたいと思います→書きました!)。通常、エクセルで使われる重回帰分析は実は“線形回帰分析”という手法で少し違うのですね。実際には目的変数が“離散変数”でも、“線形回帰分析”で分析できないこともないのですが、ここはセオリー通りに進めましょう。
そうすると、目的変数となり得る“連続変数”がないかな、と上記ローデータを眺めてもそのままではなさそうです。ここでちょっと捻りを加えるのが問題解決者のバリューです笑。上記の図3を見てみると、“この1年以内に、プライベートブランドに切り替えた食品/調味料/飲料/医薬品”は、商品ごとに(0/1)と離散変数になっています。これらを横方向に合計することで、“この1年以内に、プライベートブランドに切り替えた食品数/調味料数/飲料数/医薬品数”という連続変数の列を新たに作ることができます。これを目的変数として重回帰分析を進めましょう。
説明変数の方は、“離散変数”と“連続変数”のどちらが入っても大丈夫です。ただし“離散変数”は必ず(0/1)の形にする必要があるので、注意してください。
データ整形
それでは上記方針に基づいて、ローデータを重回帰分析用に整形していきます。
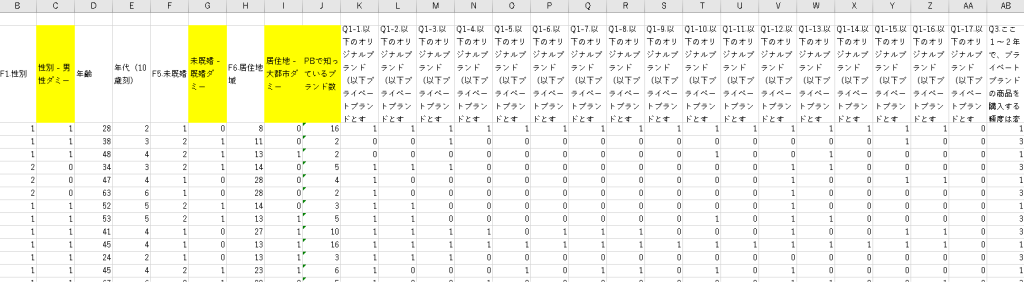
まず説明変数です。図4内のB列“性別”は(1=男、2=女)となっています。ここは(0/1)にしたいので、C列に“性別 – 男性ダミー”というダミー列を作り、B列が”1”の場合はそのまま”1”を、B列が“2”の場合は”0”を入れるように変換しています。同様にF列”未既婚“も(1=未婚、2=既婚)となっているので、G列にダミー列を作り(1=既婚、0=未婚)に変換しています。
H列“居住地”は大きな数字が入っていますが、これは具体的には47都道府県なのですね。ここも(0/1)にしたいので、ここではI列に“居住地 – 大都市ダミー”というダミー列を作り(1=東京、愛知、大阪、福岡、0=その他)というように変換しています。またK列~AB列まで個別のプライベートブランド名を挙げて(1=知っている、0=知らない)としているので、これはJ列に“PBで知っているブランド数”というダミー列を作り、K列~AB列の横方向の合計を入れています。
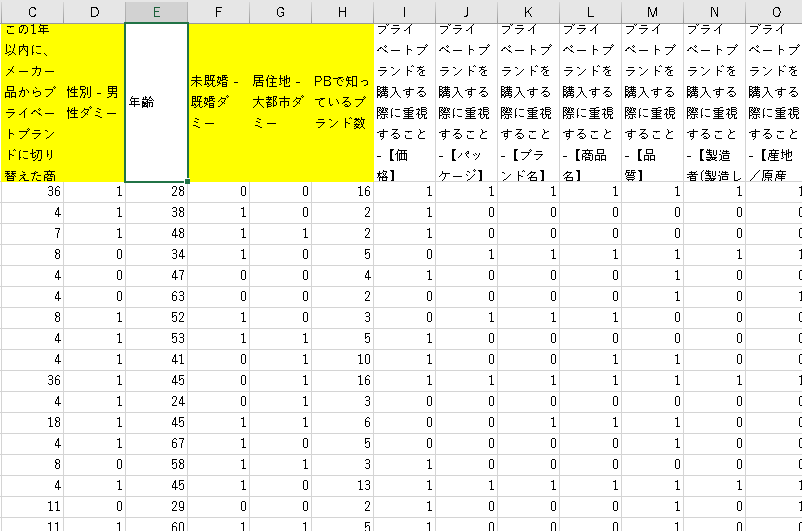
整形した結果、上記のようになりました。C列が目的変数で、上記で説明した通り“この1年以内に、プライベートブランドに切り替えた商品数”という新たに作った連続変数の列です。今回は食品/調味料/飲料/医薬品を全て合計して“商品数”にしています。
説明変数は、上記で説明した各ダミー列に加えて、E列の“年齢”は連続変数なので、そのまま残しています。またI列~O列の“PBを購入する際に重視すること”は各々(0/1)の離散変数なので、そのまま残しています。
分析
分析前の準備として“欠損値の取り扱い”と“多重共線性チェック”の2点が大事でしたよね?今回のデータは“欠損値”はなかったので大丈夫でした。それでは“多重共線性”もチェックしてみましょう。まずは相関分析です。
図5で整形したデータを使って進めます。エクセルのメニューバー「データ」→「データ分析」と選択してダイアログボックスの中から「相関」を選択します。
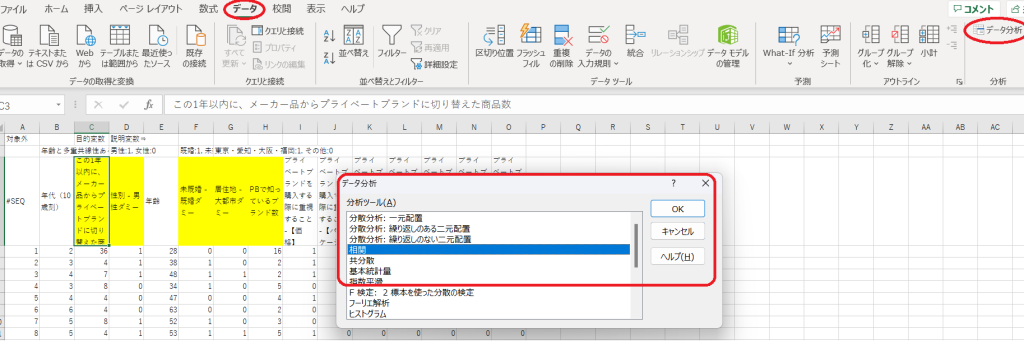
次に「相関」ダイアログボックスの中の「入力範囲」に、図5で整形したデータの範囲を指定します。「先頭行をラベルとして使用」もチェックしておきましょう。分析結果が見やすくなります。

こんな感じで、左下半分に各相関係数、右上半分が空欄で出力されますよね。この各相関係数をコピーして、「行/列の入れ替え」て貼り付けることで右上半分も埋めてください。
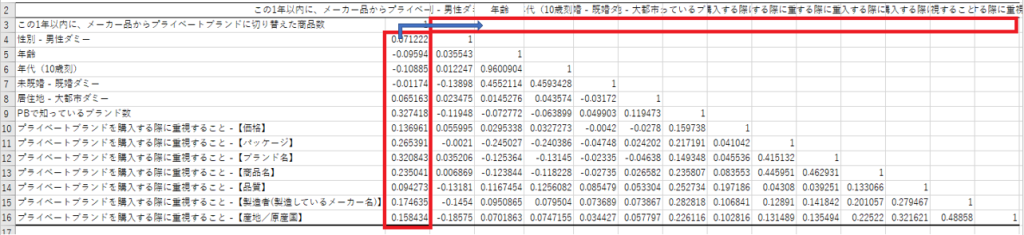
図8で作成した相関係数の表の縦軸と横軸をコピーして新たな表を作ります。表内部分は関数 ”minverse” を使うと自動的に逆行列が入ります。この逆行列表の左上から右下に至る対角線上の各セル、これらがValue Inflation Factor (VIF)です。このVIFが10を超えている部分(図9上の赤字)が多重共線性がある部分です。ここに該当する列、この例では“年齢”と“年代(10歳刻)”ですが、これらはどちらかを残して、どちらかを削除します。今回は“年齢”を残して進めます。

それではいよいよ、重回帰分析をしてみましょう!図5で整形したデータを使って進めます。図6同様、エクセルのメニューバー「データ」→「データ分析」と選択してダイアログボックスの中から、今度は「回帰分析」を選択します。
次に「回帰分析」ダイアログボックスの中の「入力Y範囲」に、目的変数であるC列、「入力X範囲」に残りの列を指定します。「ラベル」もチェックしておきましょう。分析結果が見やすくなります。

おなじみの笑、エクセルの回帰分析結果が出ました(図11)。この中で見るべきポイントは3つでしたよね?

まず“補正R2”ですが、今回は20%程度。目的変数である“この1年以内に、メーカー品からプライベートブランドに切り替えた商品数”の増減は、当分析に含めた説明変数で約20%程度説明できる、という意味です。当然100%に近い方がいいので小さく見えるかもしれませんが、ビジネス現場の実データを使って分析するとこのくらいの場合が多いと思います。10%程度でも説明できるのであれば十分示唆がある、と言っていいのではないかと思います。
次に“P-値”の列を昇順にソートし、5%未満の説明変数だけを見る対象とします。最後に、見る対象の説明変数だけを対象に、“t”列を降順にソートします。”t”が2以上が見るべき対象となります。今回は、”P-値”5%未満の説明変数の”t”はすべて2以上でしたので、これらの説明変数が目的変数へのインパクトが大きいと言えます。
PBで知っているブランド数
Priority when purchasing PB – [Brand name] / プライベートブランドを購入する際に重視すること – 【ブランド名】
性別 – 男性ダミー
プライベートブランドを購入する際に重視すること – 【パッケージ】
プライベートブランドを購入する際に重視すること – 【価格】
やはり“価格”も入ってきていますが、それよりも“ブランド認知”や“ブランド名”、“パッケージ”といった要素が大きいということが見て取れます。
まとめ
ここで冒頭、図2の集計結果を思い出すと、“やっぱり価格が大事だね”、“でも品質も過半数が挙げているよ。品質も大事だね”と読み取れましたが、”品質“については確かに単純集計では大事と言っている人は多いのですが、それらの人が実際にプライベートブランドに切り替えているかというとそうでもない、ということがわかりました。
いかがでしたでしょうか?社内の“眠っているデータ”も、今回のように少し工夫して分析してみることで、戦略の“絞り”に役立てることもできる、という事が伝わったのではないかと思います。
今回はこのくらいにさせていただき、また次回以降、続けていきたいと思います。 最後まで読んでいただき、ありがとうございました。