Hello everyone. Last time, I wrote about “KANO Model” which was introduced as one of the analysis methods when conducting primary research. This time, I would like to write about another analysis methods called “Regression Analysis”.
1. What is “Regression Analysis”?
Regression analysis is a statistical analysis method and is one of the so-called “multivariate analysis” methods. In the case of spreadsheet data such as Excel, the vertical axis is “row” and the horizontal axis is “column”. You can see the columns that have a large impact (eg: factors that have a large impact on “customer satisfaction” -> “proposal”, “price”, etc).
It can be said that it is one of the methods in the field called “data mining” in the old days and “data science” in recent years. There are so many methods in this field, and they come and go, but this regression analysis has been around for a long time and is easy to use, so I often use it. When it comes to its easiness, I think there are three points: a) Versatility, b) Clear results, and c) Easy to explain to stakeholders.
a) Versatility
Regression analysis can analyze a wide variety of data. Depending on the analysis method, there are some that cannot be used unless the data structures are well designed from the stage before collecting them (survey design stage). But in the case of regression analysis, it can be used in a vague situation like “I have this kind of data at hand, and can I utilize these in some way?”
In the case of spreadsheet data, if there are multiple “columns” and they are quantified, they can often be used (roughly speaking). Therefore, I think you can say that it is a very reassuring ally for “problem solvers” who work with various departments in the company on various projects. Also, it is helpful to be able to analyze data directly on Excel, rather than using a dedicated statistical tool! (Almost the same analysis can be done on Google Sheets by installing the add-on “XLMiner Analysis ToolPak”)
b) Clear results
Depending on the analysis method, there are methods in which the analyst needs to interpret the analysis results and name the axes, or the analyst’s subjectivity is included, but in regression analysis, the results themselves are quite digital. So if you know how to look at it, there is little room for subjectivity, I think this point is also good.
c) Easy to explain to stakeholders
I think this is a very important point for “problem solvers” to use this kind of analysis method, so I will touch on it later.
2. Key points for “Regression Analysis”
There are a lot of specific ways to proceed with the analysis on the internet, so as usual:) , let me post only one link. As you can see in this link, the execution of the analysis itself ends in an instant on Excel. I will only make two points below.
POINT1: Prep before analysis – How to handle missing values
It is common for data to contain blanks. These empty fields are called “missing values”. Regression analysis cannot be performed well with missing values, so it is necessary to remove them. There are many ways to remove them, but there are two “practical” ways.
One is to remove the records themselves that contain missing values. The problem with this method is that it reduces the number of data samples, so it is not recommended if the number of samples is not enough (about 100 or less).
The second method is to calculate the average value of the columns with blanks and fill in the blanks with the average.

With this method, the variation in the data changes slightly, but the average value remains the same, so the impact on the data distribution can be reduced. Best of all, this is easy.
Another important preparation before analysis is checking for “Multicollinearity”. This means that if there is a strong correlation between the independent variables (the three columns of “Long Cast”, “Suspension”, and “Grip strength” in the example above), it will not be possible to analyze them well. Please see this link for addressing multicollinearity.
POINT2: How to read analysis results
When you perform regression analysis on Excel, a table like this will be displayed. There may be a lot of different items that come up and you may wonder what is what, but there are only three items you need to look at.
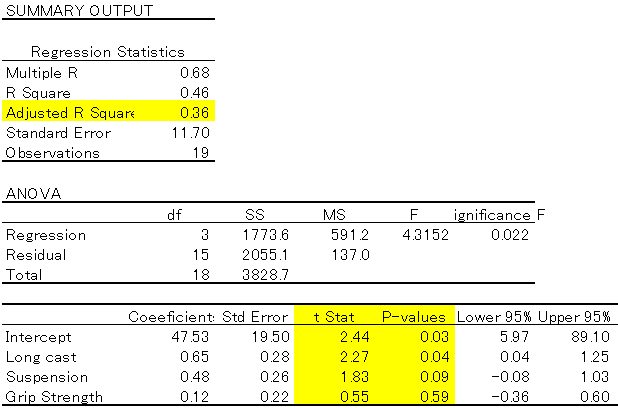
Adjusted R Square
There are “Multiple R” and “R Square” lined up, but for multiple regression, please see this one. This is the value of what percentage of the variation in the outcome variable (“Ball speed” in this example) is explained by this analysis. The closer to 100%, the better.
T-stat
The magnitude of the effect on the outcome variable. Please try to see numbers greater than 2. “Coefficient” also indicates the magnitude of the effect, but this may change depending on the unit (eg: results of 1m and 100cm might be changed), so it would be better to look at “T-stat”.
However, “Coefficient” is still important because it can be used for prediction. In the example above, Y (Ball speed) = 0.65×1 (Long cast) + 0.48×2 (Suspension) + 0.12×3 (Grip strength) + 47.53. This prediction formula means, for example, if the “Long cast” extends 1m, the ball speed will increase by 0.65km.
P value
Only look at data that are less than 5%. This is the probability of variation occurring, and if more than 5%, the probability would be high.
3. How to explain to stakeholders
As I wrote earlier, it is important for you, the “problem solvers,” to explain your analysis results to project stakeholders so that they can understand them. When using advanced statistical methods such as regression analysis, this part often becomes a bottleneck, so I think it is important to prepare an explanation way.
We are often asked about the difference from correlation analysis. Similar to regression analysis, correlation analyzes data that includes multiple columns, but correlation only shows the strength of the relationship between columns (eg: 0.3 is weak, 0.8 is strong, etc).
In contrast, regression analysis shows causality. Regression analysis is basically Y=ax1+bx2+cx3…+d, which we learned in mathematics long time ago. Y = Outcome variable, a, b, c = Coefficient (also called independent variable), d = Intercept. What this means is that you can predict the outcome variable by changing the coefficient. This is the big difference from correlation. I think it’s best to understand this first.
Strictly speaking, the multiple regression analysis shared here is called linear regression analysis, and the outcome variable must be a continuous variable. If your outcome variable is discrete, you should use logistic regression analysis. Learn more about logistic regression analysis here.
That’s all for this time, and I would like to continue from the next time onwards. Thank you for reading until the end.